Hướng Dẫn Đánh Giá Chuẩn Production Cho Hệ Thống RAG

Table of Contents9 sections
Khi xây dựng một hệ thống Retrieval-Augmented Generation (RAG), chúng ta thường dành rất nhiều thời gian để tối ưu Prompt, chọn LLM mạnh nhất, hay tinh chỉnh tham số Chunking. Thế nhưng, có một thành phần thầm lặng quyết định trực tiếp đến việc LLM có trả lời đúng hay không: Embedding Model.
Trong môi trường học tập hay khi đi làm dự án, một câu hỏi kinh điển mà các Thầy cô hội đồng hoặc Khách hàng luôn đặt ra cho bạn là:
"Tại sao em/anh lại chọn model Embedding của OpenAI (text-embedding-3-small) mà không dùng bge-m3 của Beijing Academy? Dựa trên cơ sở dữ liệu nào để khẳng định model này tối ưu hơn cho bài toán của chúng ta?"
Nếu câu trả lời của bạn chỉ dừng lại ở: "Vì em thấy mọi người hay dùng" hoặc "Vì model này điểm MTEB cao", bạn đã thất bại trong việc chứng minh năng lực thiết kế hệ thống. Để giải quyết triệt để bài toán này, bài viết dưới đây sẽ cung cấp cho bạn một Framework đánh giá mô hình Embedding chuẩn Production, cân bằng giữa Chất lượng (Quality), Hiệu năng (Performance), và Đặc thù Ngôn ngữ (Tiếng Việt).
1. Bản chất của việc Đánh giá Embedding trong RAG
Trong nghiên cứu (R&D), người ta đánh giá mô hình Embedding bằng các bài test độ tương đồng vector thuần túy. Nhưng trong RAG, mô hình Embedding đóng vai trò là Bộ truy xuất (Retriever). Vì vậy, cách đánh giá đúng nhất là đánh giá Downstream Task (Kết quả đầu ra của quá trình tìm kiếm thông tin).
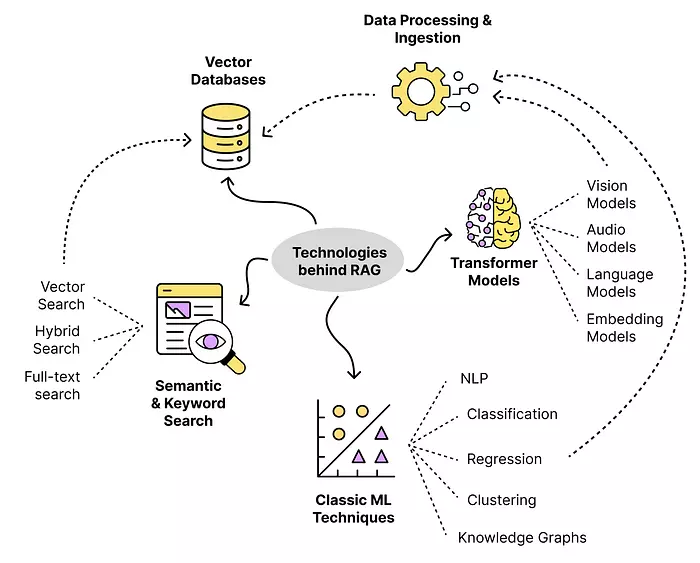
Hình 1: Mô tả kiến trúc cơ bản của một hệ thống RAG
Để trả lời câu hỏi của khách hàng bằng con số định lượng, việc đầu tiên bạn cần làm là xây dựng một Golden Dataset (Tập dữ liệu chuẩn).
Cách xây dựng bộ Golden Dataset nhanh cho dự án:
Tập dữ liệu này gồm các cặp: (Câu hỏi của User, Đoạn văn bản chứa câu trả lời đúng, ID tài liệu).
Cách thủ công: Tự lọc ra khoảng 100-200 câu hỏi thực tế từ người dùng hoặc tài liệu nội bộ.
Cách tự động (LLM-as-a-Judge): Sử dụng các framework như Ragas hoặc TruLens. Bạn nạp tài liệu của mình vào, bắt GPT-4 đóng vai người dùng để tự động sinh ra 500 cặp Câu hỏi - Câu trả lời dựa trên chính tài liệu đó.
2. Trụ cột 1: Các chỉ số Chất lượng Truy xuất (Retrieval Quality Metrics)
Khi đã có Golden Dataset, bạn cho các mô hình Embedding ứng viên (Model A, Model B) chạy qua tập dữ liệu này và đo đạc các chỉ số sau để "nói chuyện bằng con số" với khách hàng:
Hit Rate @K (Tỷ lệ đánh trúng): Định nghĩa đơn giản là trong top K (ví dụ: top 3, top 5) đoạn văn bản mà Embedding tìm về, có chứa đoạn văn bản đúng hay không. Hit Rate càng cao chứng tỏ model không bỏ sót thông tin quan trọng.
MRR (Mean Reciprocal Rank): Chỉ số này quan tâm đến việc đoạn văn bản đúng nhất nằm ở vị trí thứ mấy. Nếu nó nằm ngay Top 1, điểm sẽ là 1. Nếu nằm ở Top 3, điểm là 1/3. Trong RAG, MRR cực kỳ quan trọng vì nếu thông tin đúng nằm càng trên top, LLM càng ít bị hiện tượng "Lost in the Middle" (bị loãng thông tin).
NDCG @K (Normalized Discounted Cumulative Gain): Chỉ số chấm điểm nâng cao, đánh giá xem thứ tự sắp xếp của các tài liệu trả về đã tối ưu chưa (tài liệu liên quan nhiều phải xếp trên tài liệu liên quan ít).
Lời khuyên thực chiến: Khách hàng không cần hiểu NDCG là gì. Bạn chỉ cần trình bày: "Qua thực nghiệm trên 500 câu hỏi mẫu của công ty, Model A đạt Hit Rate@3 là 85% (nghĩa là 100 câu thì 85 câu tìm đúng tài liệu trong top 3), cao hơn Model B 10%."
3. Trụ cột 2: Thử thách Ngôn ngữ (The Multilingual & Vietnamese Challenge)
Hầu hết các tài liệu RAG doanh nghiệp tại Việt Nam đều sử dụng tiếng Việt hoặc dạng song ngữ (Anh - Việt). Đây chính là "hố tử thần" nơi các model đứng top bảng xếp hạng thế giới (MTEB) thường bị đánh bại bởi các model chuyên dụng.
Khi đánh giá cấu phần này, bạn cần đưa vào Golden Dataset các trường hợp test độ bền bỉ (Robustness Testing):
Từ lóng và Teencode: Model có hiểu các từ viết tắt chuyên ngành, hoặc cách gõ lỗi không?
Cú pháp tiếng Việt: Tiếng Việt là ngôn ngữ đơn lập, ý nghĩa phụ thuộc vào ngữ cảnh cấu trúc câu. Các model như
bge-m3hoặccohere-embed-multilingual-v3thường xử lý ngữ cảnh Đông Nam Á tốt hơn các model đời cũ chỉ chuyên tiếng Anh.Đoạn văn lai căng (Code-switching): Trong văn bản kỹ thuật hoặc e-commerce, việc viết "gọi API", "tối ưu hóa database" diễn ra liên tục. Bạn phải kiểm tra xem mô hình có mapping được từ tiếng Anh kỹ thuật sang khái niệm tiếng Việt tương đương hay không.
4. Trụ cột 3: Hiệu năng Hệ thống và Bài toán Kinh tế (Performance & Cost)
Một mô hình cho độ chính xác cao hơn 2% nhưng làm tăng gấp đôi hóa đơn tiền điện hoặc khiến chatbot phản hồi chậm thêm 1 giây thì hoàn toàn không có giá trị thương mại.
Hãy lập bảng so sánh dựa trên các tiêu chí kỹ thuật hệ thống sau:
Tiêu chí đánh giá | Bản chất kỹ thuật | Tác động đến Production |
|---|---|---|
Latency (p95, p99) | Thời gian tạo vector cho một request văn bản. | p99 > 500ms sẽ khiến trải nghiệm chat bị giật lag rõ rệt. |
Embedding Dimension | Số chiều của Vector (384, 768, 1536, 3072). | Số chiều càng lớn càng tốn RAM/Dung lượng lưu trữ trên Vector DB (Qdrant, Milvus), làm chậm tốc độ tìm kiếm (Search Latency). |
Max Token Context | Giới hạn độ dài văn bản đầu vào (512, 8192 tokens). | Nếu chunk size của bạn là 1024 nhưng model chỉ nhận 512, văn bản sẽ bị cắt cụt, gây mất thông tin. |
Cost Scaling | Trả tiền theo Token (API) hay tiền Thuê hạ tầng (Self-hosted GPU). | Bài toán chi phí dài hạn khi hệ thống scale lên triệu tài liệu. |
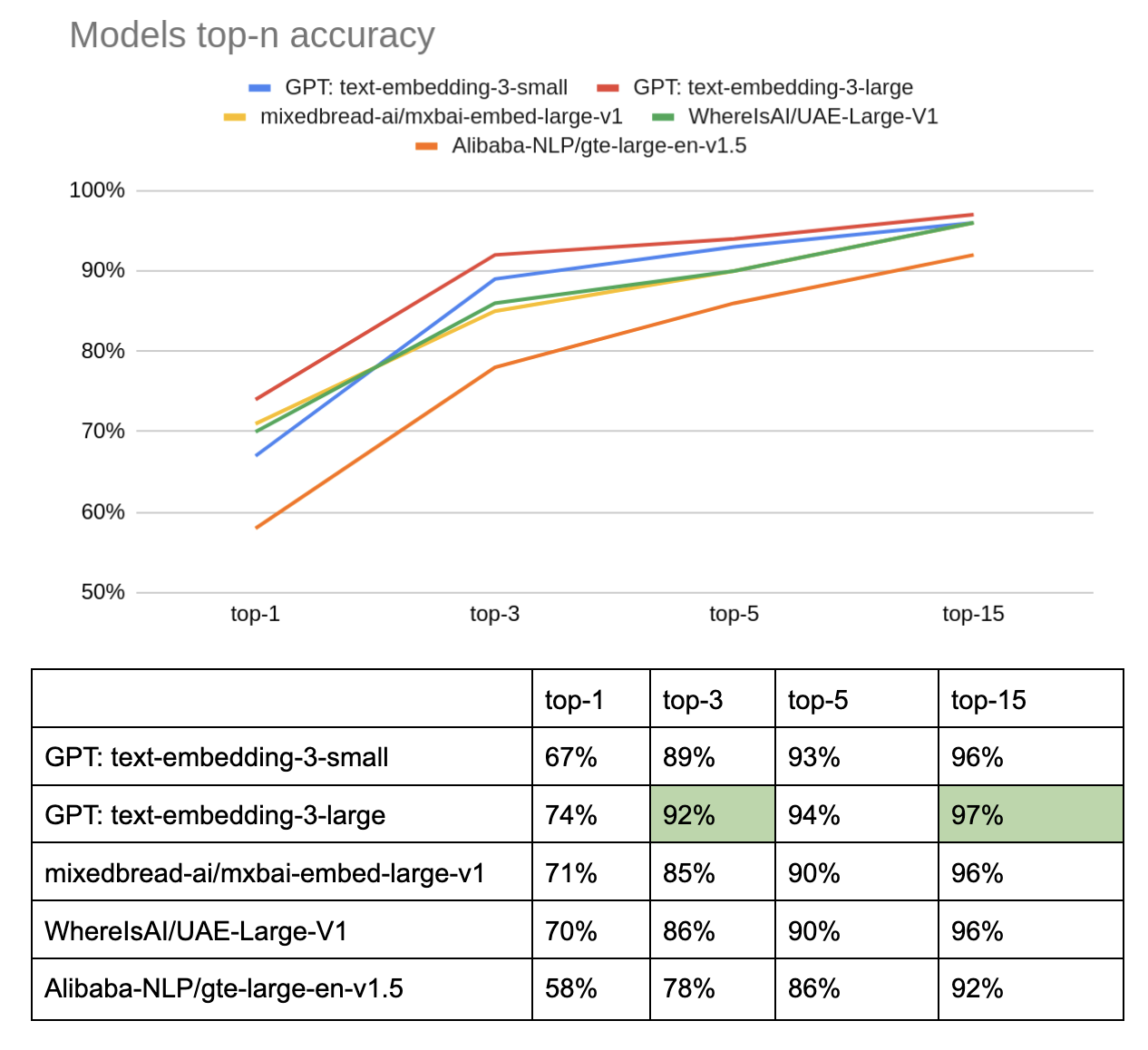
Hình 2: Biểu đồ so sánh accuracy giữa các model embedding
Kỹ thuật tối ưu nâng cao cho Production bạn nên biết:
Matryoshka Embeddings: Các model mới như
text-embedding-3-smallcủa OpenAI cho phép bạn cắt giảm số chiều vector (ví dụ từ 1536 xuống 256) mà vẫn giữ lại đến 90-95% độ chính xác. Điều này giúp giảm tới 6 lần chi phí lưu trữ Vector DB.ONNX / TensorRT Quantization: Nếu chọn dùng model Open-source (như dòng BGE), việc chuyển đổi model sang định dạng ONNX và lượng tử hóa (Quantization từ FP32 xuống INT8) giúp tăng tốc độ tạo vector lên từ 2-4 lần trên môi trường Production.
5. Quy trình 3 bước thuyết phục Khách hàng / Thầy cô
Để không ai có thể bẻ gãy được lập luận chọn mô hình của bạn, hãy triển khai quy trình đánh giá theo cấu trúc 3 tầng chặt chẽ sau:
Bước 1: Offline Evaluation (Đo đạc trên dữ liệu mẫu)
➔ Kết quả: Chọn ra Top 2 model có NDCG và Latency tốt
▼
Bước 2: Shadow Deploy / Mirroring
➔ Kết quả: Test tải thực tế, đo p99 Latency
▼
Bước 3: Đưa ra Kiến nghị dựa trên ROI (Học tập/Kinh tế)
➔ Kết quả: Bản báo cáo thuyết phục Khách hàng Tầng 1 - Offline Evaluation: Chạy bộ dữ liệu Golden Dataset qua mã nguồn kiểm thử nội bộ. Đo chỉ số Retrieval (Hit Rate, MRR) và ghi nhận kết quả thô.
Tầng 2 - Shadow Deploy (Triển khai bóng mờ): Khi đưa hệ thống lên môi trường staging/production, bạn cho cả 2 model chạy song song. Khi User gửi câu hỏi, hệ thống gửi đến cả Model A và Model B, nhưng chỉ lấy kết quả Model A trả về cho User. Mục đích là để đo xem dưới áp lực tải thực tế (nhiều người dùng cùng lúc), hạ tầng của bạn có chịu nổi không, độ trễ p99 thực tế là bao nhiêu.
Tầng 3 - Đưa ra kiến nghị dựa trên ROI (Return on Investment): Ghép sơ đồ chi phí và chất lượng lại với nhau để đưa ra kết luận cuối cùng.
Mẫu câu trả lời "Hạ gục" mọi phản biện:
*"Báo cáo anh/chị, chúng tôi đã tiến hành thực nghiệm song song giữa Model A (Cloud API) và Model B (Open-source tự host) trên bộ 500 tài liệu nội bộ của công ty.
Về chất lượng, Model A có điểm Hit Rate@3 vượt trội hơn 8% so với Model B, đặc biệt xử lý rất tốt phần thuật ngữ tiếng Việt lai tiếng Anh trong tài liệu kỹ thuật của chúng ta. Về mặt vận hành, dù Model A tốn chi phí API theo lượng dùng, nhưng nó giúp chúng ta tiết kiệm được khoảng $300/tháng tiền thuê cụm GPU cố định để host Model B, đồng thời giảm thời gian bảo trì hệ thống (DevOps Load) xuống mức tối thiểu. Vì vậy, trong giai đoạn MVP này, Model A là lựa chọn tối ưu nhất về cả kỹ thuật lẫn kinh tế."*
Lời kết
Trong kỷ nguyên GenAI, việc lắp ghép một hệ thống RAG chạy được chỉ mất 30 phút. Nhưng để đưa hệ thống đó lên Production và chạy một cách ổn định, hiệu quả, tiết kiệm thì lại là câu chuyện hoàn toàn khác. Đánh giá mô hình Embedding bằng những con số định lượng chính là bước phân hóa giữa một "Developer chép code mẫu" và một "AI Engineer thực thụ".
Hy vọng Framework này sẽ giúp bạn làm chủ cấu phần Retrieval trong hệ thống RAG của mình và bảo vệ thành công dự án trước mọi hội đồng phản biện!