Understanding RAG: The Future of AI-Powered Knowledge Systems

On this page29 sections
AI RAG là gì? Vì sao Retrieval-Augmented Generation đang thay đổi cách xây dựng ứng dụng AI
AI đang phát triển cực nhanh, nhưng một vấn đề lớn vẫn luôn tồn tại:
LLM (Large Language Model) thường trả lời sai, tạo ra thông tin không có thật (hallucination), hoặc không biết dữ liệu mới sau thời điểm được train.
Đây chính là lý do công nghệ RAG (Retrieval-Augmented Generation) ra đời.
RAG là gì?
RAG (Retrieval-Augmented Generation) là kiến trúc kết hợp giữa:
Retrieval → tìm kiếm dữ liệu liên quan
Generation → dùng AI sinh ra câu trả lời
Thay vì để AI trả lời hoàn toàn bằng “kiến thức đã học”, RAG cho phép AI:
Tìm kiếm dữ liệu thực tế từ database/document
Đưa dữ liệu đó vào prompt
Sinh câu trả lời dựa trên context mới nhất
Ví dụ đơn giản
Giả sử bạn xây chatbot cho công ty.
Nếu dùng AI thuần:
“Chính sách nghỉ phép công ty là gì?”
LLM có thể:
đoán
trả lời sai
hoặc không biết
Nếu dùng RAG:
Hệ thống tìm đúng file HR policy
Trích xuất đoạn liên quan
Đưa vào AI
AI trả lời chính xác dựa trên tài liệu thật
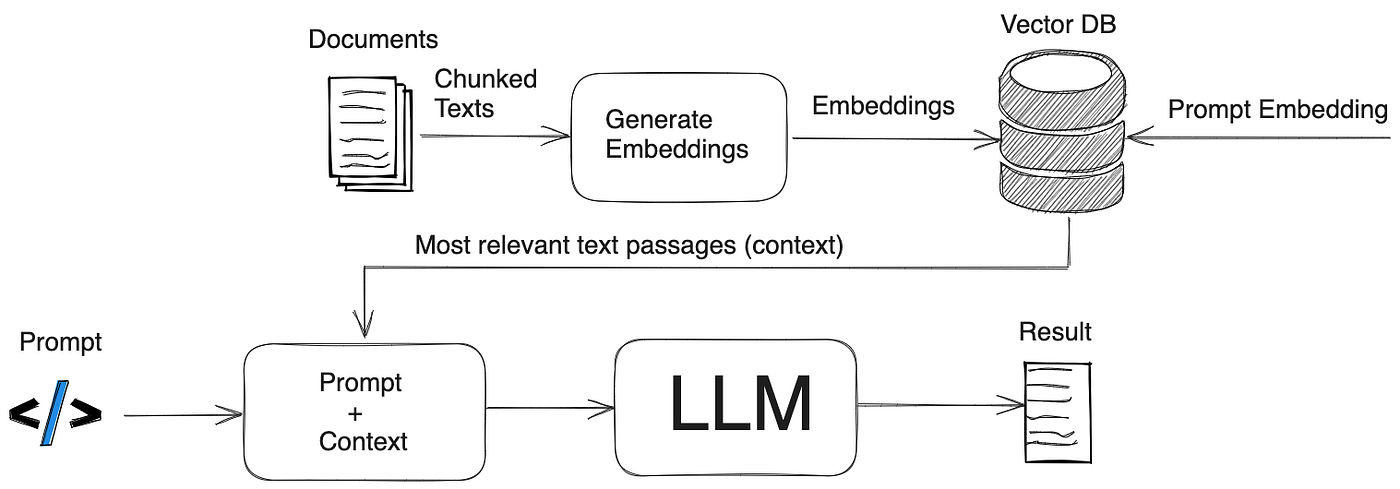
Kiến trúc tổng quan của RAG
User Question
↓
Embedding Model
↓
Vector Database Search
↓
Retrieve Relevant Documents
↓
LLM Prompt Construction
↓
AI Generated AnswerThành phần chính trong hệ thống RAG
1. Embedding Model
Embedding là quá trình biến text thành vector số học.
Ví dụ:
"AI engineer"
↓
[0.123, -0.883, 0.551, ...]Các vector có ý nghĩa giống nhau sẽ nằm gần nhau trong không gian vector.
Popular models:
OpenAI text-embedding-3-small
BGE
E5
Instructor
ViNTERN (multimodal)
2. Vector Database
Sau khi convert tài liệu thành vector, cần nơi để lưu trữ và tìm kiếm semantic search.
Popular vector databases:
ChromaDB
Pinecone
Weaviate
Qdrant
Milvus
Elasticsearch Vector Search
3. Retriever
Retriever chịu trách nhiệm:
tìm các đoạn text liên quan nhất
dựa trên semantic similarity
Ví dụ:
Top K = 5Hệ thống sẽ lấy 5 đoạn gần nhất để đưa vào prompt.
4. Large Language Model (LLM)
LLM sẽ:
đọc context được retrieve
tổng hợp
sinh câu trả lời tự nhiên
Ví dụ:
GPT-4o
Claude
Gemini
Llama 3
Qwen
Flow hoạt động thực tế
Bước 1 — Ingestion dữ liệu
Tài liệu được:
đọc từ PDF / DOCX / Database
chunk nhỏ
convert embedding
lưu vào vector DB
Bước 2 — User query
User đặt câu hỏi:
"Làm sao deploy ECS với private API Gateway?"Bước 3 — Semantic Search
System:
convert query thành vector
search top-k chunks liên quan
Bước 4 — Prompt Augmentation
Prompt sẽ được build như:
Answer based on the following context:
[Retrieved Context]
Question:
[User Question]Bước 5 — Generate Answer
LLM tạo câu trả lời grounded theo dữ liệu thực.
Vì sao RAG quan trọng?
1. Giảm hallucination
AI không cần “đoán”.
Nó trả lời dựa trên:
document thật
knowledge base thật
2. Không cần retrain model
Bạn không cần fine-tune mỗi lần dữ liệu thay đổi.
Chỉ cần:
update vector DB
re-index documents
3. Dữ liệu luôn mới
LLM có knowledge cutoff.
RAG giúp:
truy cập tài liệu mới
đọc dữ liệu realtime
kết nối internal systems
4. Phù hợp enterprise
RAG cực mạnh cho:
chatbot nội bộ
knowledge management
document assistant
customer support
AI search engine
Các use case phổ biến
AI Chatbot nội bộ
Chat với:
policy
technical docs
wiki
SOP
AI Coding Assistant
Search:
source code
architecture docs
ADR
API specs
AI Customer Support
AI đọc:
FAQ
product docs
tickets
để trả lời chính xác hơn.
AI Search Engine
Semantic search thay vì keyword search truyền thống.
Những vấn đề thực tế khi build RAG
1. Chunking không tốt
Chunk quá lớn:
tốn token
search kém chính xác
Chunk quá nhỏ:
mất context
2. Retrieval quality thấp
Nếu retrieve sai:
AI sẽ trả lời sai
Garbage in → garbage out.
3. Context window limitation
LLM chỉ đọc được lượng token giới hạn.
Cần:
reranking
filtering
compression
4. Chi phí
RAG production cần:
embedding cost
vector DB
inference cost
Advanced RAG
Khi hệ thống lớn hơn, thường sẽ có:
Hybrid Search
Kết hợp:
semantic search
keyword search (BM25)
Reranking
Dùng model khác để:
re-score documents
improve relevance
Multi-Query Retrieval
AI tự generate nhiều query để search tốt hơn.
Agentic RAG
LLM có thể:
tự quyết định cần search gì
search nhiều bước
reasoning trước khi trả lời
RAG vs Fine-tuning
RAGFine-tuningDùng external knowledgeUpdate knowledge vào modelDễ update dữ liệuKhó retrainRẻ hơnTốn GPUPhù hợp document QAPhù hợp behavior tuningReal-time dataStatic knowledge
Tech stack phổ biến hiện nay
Backend
Node.js / NestJS
Python FastAPI
AI Framework
LangChain
LlamaIndex
Haystack
Vector DB
Pinecone
Qdrant
Chroma
LLM
OpenAI
Claude
Gemini
Ollama local models
Một kiến trúc RAG production phổ biến
Tương lai của RAG
RAG đang trở thành nền tảng cho:
AI agents
AI search
enterprise copilots
autonomous systems
Xu hướng mới:
Multimodal RAG
Graph RAG
Agentic RAG
Long-context RAG
Real-time streaming RAG
Kết luận
RAG không chỉ là “chat với document”.
Đây là kiến trúc cực kỳ quan trọng giúp AI:
đáng tin cậy hơn
cập nhật dữ liệu mới
phù hợp môi trường doanh nghiệp
giảm hallucination
scale production systems
Nếu LLM là “bộ não”,
thì RAG chính là cách giúp AI có thể:
đọc tài liệu thật
hiểu context thật
và trả lời dựa trên dữ liệu thực tế.